系统学习运营课程,加入《91运营网VIP会员》,开启365天运营成长计划>
系统学习运营课程,加入《91运营网VIP会员》,开启365天运营成长计划
本文将以抖音为案例,聊聊什么是用户增长实验,它能达到什么作用,以及如何进行用户增长实验。希望对你有所启发。

用户增长(UG)核心工作流是:分析数据→形成假设→实验验证。而本文将用一个大家可能注意到过的案例,来尝试逆推和重现相关的工作场景,争取讲清楚UG实验在做什么。
在刷抖音时部分用户可能会留意到,完成2次播放后分享按钮变成了自己的好友头像,而部分用户依然是常规的分享图标。
对了,这就是一个简单的UG实验。实验涉及到的环节是类似的,我们不妨拿这个例子来做代表,主要讲:
案例重点讲每一步应该做什么,具体数值是杜撰的且并不重要,如有雷同纯属巧合。
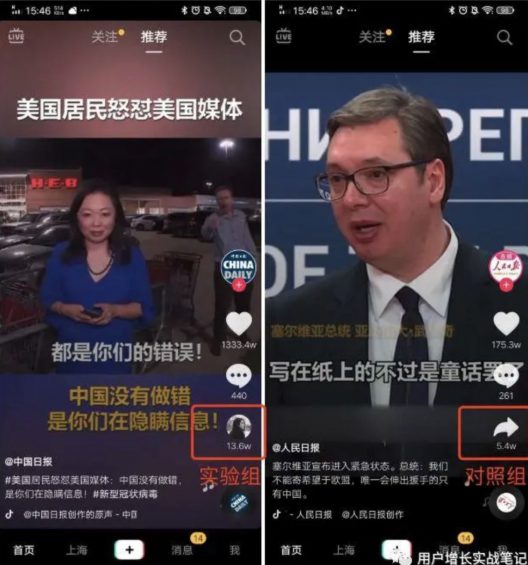
不难看出,直接目的是提升用户点击分享按钮的比例(分享率)。而用最常分享的「好友头像」替换「分享按钮」是否能提升分享率,需要实验来验证。
曾经了解过一些经验:用户群的互动率(转评赞的用户占比)与其留存率很好的正相关。
假想你的微信好友很少,没有收到信息,你还会经常打开吗?假设你每次发朋友圈,没人点赞评论,势必会大大削弱发圈的积极性。
所以,抖音这么做,更进一步的目标应该是提升用户留存,而留存和用户规模又高度相关,策略的最终目标应该还是提升DAU、时长、收入这些规模数据。
这些都是前期分析数据的关键产出,而「提升分享率能够提升DAU和时长」是一个假设,需要实验验证。
这个实验虽小,但是它背后关联到最核心的增长目标。实验效果的评估,我们也需要关注到这些「结果指标」,而不仅仅是分享按钮的点击率、分享完成率、分享的回流率等等「过程指标」。
我们通常会使用随机对照实验,市面上大家基本上用AB实验来代指随机对照实验。通过对比实验组和对照组的指标差异,来验证下发不同策略的两组间,是否产生了显著差异。
通常将用户ID(通常是在用户首次使用app时自动生成的一个字符串)经过一些随机算法(常用hash算法)的处理,理论上保证用户的特征与随机算法处理后的用户ID不存在依赖关系,最后依据处理后ID进行分组。
即便如此,分组的充分随机,依然是一个行业难题,所以会通过实验前的空跑期或叫AA实验来确认不同组间在实验前是否无偏差。
这个案例只关心到随机分组,假设我们随机从大盘活跃用户中取了一部分人群,再随机分为实验组和对照组,就可以开始实验了。

实际工作中,往往会碰到流量少,而同时需要做的实验多,这就需要引入正交分层。分层的目的在于形成一系列互不干扰的「平行宇宙」,便于在流量不足时,同时进行很多实验。
这个案例没这么复杂,只需要将实验组下发「分享按钮替换为朋友圈头像」的指令,而对照组下发「保持原状」的指令。
实际工作中,还会碰到多个实验变量,如果需要评估每一个变量的影响,就需要确保存在「仅有一个变量差异」的两个实验组。
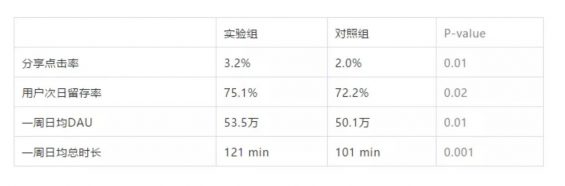
回归到实验目的,我们直接关注分享率的提升,进一步关注用户留存率的提升,最后想看到对用户DAU、时长等是否有提升。那我们需要关注的指标就有:
判断实验结果是否可信,涉及到一个「显著性」的概念,即实验组和对照组的指标差异是不是能满足统计显著性。
统计显著性,意味着我们看到的提升,并不是因为随机波动造成,而是策略影响的。
评估显著性,通常用表2中的P-value、统计功效等来说明,完善的实验平台,可以直接输出差异是否显著的结论。如果对显著性感兴趣,建议大家找一本统计学的书详细了解。
参照表2中的数据,基本上可以说明该策略能够显著提升分享率、次留、DAU和时长。
样本量足够大时,即使很小的差异也可能是置信的;而样本量太小时,即使比较大的差异,也可能是不置信的。只要分组充分的随机,样本量大更可能得到置信的结果,但是受限于各方面的成本考量,我们往往需要评估选择多少样本量。
这里就涉及到一个「最小样本量」的问题:通过对实验差异的预估,推算出每一组用最少用多少样本量才能确保实验结果差异是置信的,而不是随机的误差。
相关地,还会涉及到一个「实验时长」的问题,简单来说,实验时长=最小样本量/每日流量。
UI 修改带来的点击提升,通常可能是新奇效应,所以我们的实验尽量拉长至两个以上的用户活跃周期。比如某些用户是周末刷短视频,周中很少刷,使用频次的一个完整的活跃周期就是一周。
新奇效应通常最多持续一个活跃周期,我们选择观察两个活跃周期,大概率能看到用户回归常态下的最终提升量。当然,如果有必要,我们也可以保持这两个实验组和对照组长期有效,看更长久的影响。
实验完成后,我们通常可以收到很多结果,如果不做及时的复盘,这些数据的价值很可能只是冰山一角。这一部分,我跳出本篇的抖音案例来说。
及时复盘帮助我们尽早的知道策略是否有效,甚至尽早反推实验是不是设计合理。
通常用户量足够大时,很小的指标提升也是置信的,但实际上可能对增长目标帮助不大。我们需要横向来对比不同策略,对同一指标的提升效果,决定哪一个更好。
假设实验差异不置信,增长策略从下发到生效是一个「链条」,在哪个节点断掉了?为什么?及时复盘能够尽快明确是策略没成功下发,还是策略无效果。
很多时候我们初看数据会得到实验差异不显著,效果提升不明显的结果。但是这不妨碍我们去做进一步的挖掘:哪些人群更有效、哪些人群没有效果,可通过实验下钻得到初步答案,再针对有效人群设计新的实验去重复验证,针对无效人群做进一步的分析,进一步调整策略。
实验下钻依赖于我们对用户属性有初步的标签,在实验分析时能够用户进行下钻,或者说筛选。
需要强调:下钻后用户量少,不能保证置信度;另一方面这种“后验”的方式会存在分组不均的潜在风险,需要我们针对下钻结果重复去做实验,才能得到可靠的结论。
通过漏斗分析,我们可以看到策略的断点,策略是在哪一步开始失效的。通过产品优化(页面加载、按钮样式、引导样式、文案等等)、运营优化(调整策略下发时机、频次;调整参数如金额、展现时长等等)。
这一部分是产品经理最为擅长的,UG无非是强调基于准确结论来判断问题的关键,去高优先级推进最关键的迭代。
一个实验结束,我们能够得到的应该远超过实验指标提升。上升到对用户价值提升的视角,这些策略之所以有用,是在哪些地方提升了用户价值,是新体验远超过了旧体验,还是极大降低了用户成本?这些认知是否有可能推广到相关领域、推广到类似场景?
这些我认为是UG更大的课题,也需要产品经理们更多的思考、总结和新的尝试,这同时也是数据驱动的价值和乐趣~
勾搭小编微信号yueyingzheng88,加入91运营官方社群,会运营的人都在这里了
- 本文固定链接: http://douyinyunying.cc/?id=12214
- 转载请注明: admin 于 抖音运营 发表
《本文》有 0 条评论