今天这期我们依旧来继续我们机器学习的话题,这期的内容对大家来说可能会熟悉一点,就是我们老生常谈的
本篇推文带有作者强烈的主观想法,欢迎各位小伙伴在评论区讨论哦,如果各位对于机器学习有感兴趣的方向,也欢迎在评论区留言,说不定下一个推文主题就是你感兴趣的话题哦
想白嫖单细胞生信文章?这五大源头数据库,是你发文章的源泉!高频预警!你一定要收藏!
好家伙!90%以上审稿人都会问到的问题,今天帮你解决!就是这么齐齐整整!
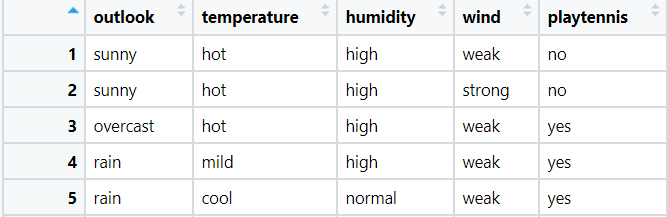
首先,我们需要有一个基本的概念,贝叶斯不是一种模型,而是一类模型,是一类基于贝叶斯算法的模型,我们最常使用的是其中的一种模型被称为朴素贝叶斯(Naive Bayes)
后面会讲解算法的一些由来,大家如果觉得太长,只需要记住这句话也可以完成分析,贝叶斯属于有监督学习中执行分类的算法,在输入数据的要求上要求我们的自变量最好是离散型变量,但是如果你是连续型变量也是可以的,要么就把连续型变量转为离散型变量,要么就假设离散变量符合正态分布,然后计算每个变量的概率密度函数,然后根据贝叶斯算法的基本逻辑用先验概率来对后验概率进行分类,如果能理解上面这些,下面这块故事可以选择性阅读哦
贝叶斯算法来自于一个人的名字——托马斯.贝叶斯,其实是为了解决一个问题。以下摘自wikipedia上的简介
所谓的贝叶斯方法源于他生前为解决一个“逆概”问题写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆概问题。
即我们可以把这个问题再贴近生活一下,当气象学家提供天气预报时,通常使用“70%的降雨几率”等术语来预测降水。这些预测被称为降水的概率。你有没有考虑过人们是如何计算它们的?这是一个令人费解的问题,因为实际上,它要么下雨要么不下雨。
他们使用过去事件的数据来推断未来的事件。就天气而言,降雨的机会描述了以前具有类似可测量的大气条件的降水发生的比例。因此,70%的降雨机率意味着,假设在过去10例天气模式相似的情况下,有7例的降水发生
其实我们如果简单的学过统计,我们其实可以自然而然的推导出贝叶斯的算法公式,晨曦这里简单的推导一次,大家如果感兴趣可以跟着晨曦推导一次,如果不感兴趣,可以直接往下滑到代码实战部分
我们这里借用wikipedia上的一个例子来帮助我们理解贝叶斯的推导方式
一所学校里面有 60% 的男生,40% 的女生。男生总是穿长裤,女生则一半穿长裤一半穿裙子。有了这些信息之后我们可以容易地计算“随机选取一个学生,他(她)穿长裤的概率和穿裙子的概率是多大”,这个就是前面说的“正向概率”的计算。然而,假设你走在校园中,迎面走来一个穿长裤的学生(很不幸的是你高度近似,你只看得见他(她)穿的是否长裤,而无法确定他(她)的性别),你能够推断出他(她)是男生的概率是多大吗?
我们来计算一下,假设学校里面有Z个人,60%的男生都穿长裤,所以穿长裤的男生为Z✖P(男生)✖P(长裤男生),40%的女生里面又有一半(50%)穿长裤,所以我们可以得到女生穿长裤为Z✖P(女生)✖P(长裤女生)
注意,如果把上式收缩起来,分母其实就是 P(Pants) ,分子其实就是 P(Pants, Girl) 。而这个比例很自然地就读作:在穿长裤的人( P(Pants) )里面有多少(穿长裤)的女孩( P(Pants, Girl) )
但其实贝叶斯的本质就是一句话:是将未知的条件概率 P(BA)转换为已知的条件概率P(AB)
好,到这里我们就大致了解了贝叶斯的推导过程,当然,仅仅了解即可,因为我们有现成的R包可以帮助我们完成上述的操作
(1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化医学即可!)
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
然而,在大多数情况下,当这些假设被违反时,朴素贝叶斯的表现仍然相当好。即使在特征之间存在很强依赖关系的极端情况下,这也是如此。由于该算法在多种条件下的多功能性和准确性,朴素贝叶斯算法通常是分类学习任务的第一候选算法
这里我们还需要介绍因为贝叶斯模型都是相乘的形式,所以一旦某个变量发生的机率为0那么很显然我们获得的最后的概率就是0,这显然是我们不想看到的,所以我们会使用一种叫做拉普拉斯的估计量,拉普拉斯估计器本质上为频率表中的每个计数添加了一个小数字,从而确保每个特征对每个类具有非零的概率。通常,拉普拉斯估计器被设置为1
由于朴素贝叶斯使用频率表来学习数据,因此每个特征都必须是分类的,以创建组成矩阵的类和特征值的组合。由于数值特征没有值的类别,所以前面的算法不能直接用于数值数据。然而,有一些方法可以解决这个问题,一种选择是使用分位数离散特征。您可以将数据分成三个带分位数的箱子,四个带四分位数的箱子,或者五个带五分位数的箱子
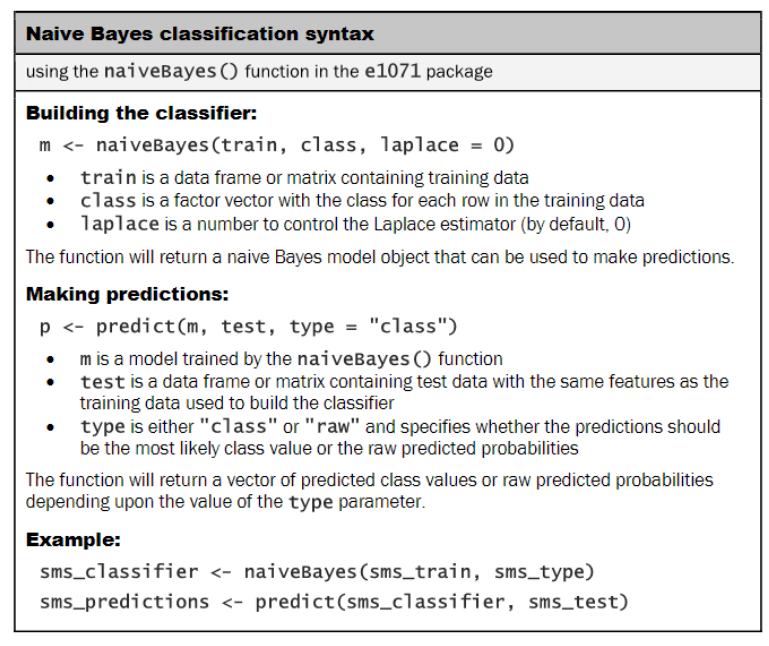
其实我们会发现,我们没有设置拉普拉斯,这样的线%存在,那么显然就会导致模型的失败
tidymodels包整体的流程就在这里,晨曦并没有放置结果,大家在推文最后回复相关关键词获得代码以后,可以回去自己运行~
Ps:大家的留言晨曦都看到了,等再连载几期机器学习,就给大家更新tidymodels包以及mlr3包的相关教程,期待哦~
那么这里我们仍然不可避免来思考一个问题,就是如果我们的样本量很少,连续型数据无法进行离散化处理应该怎么办?
本身来说有监督学习的模型可以分为生成模型和判别模型,生成模型可以转换为判别模型,反之则不可以,本身来说贝叶斯构建的生成模型转换成判别模型的时候即可以进行针对连续型数据的判断
至此,我们就通过基于贝叶斯算法的贝叶斯判别来解决了连续型变量不能离散化的问题
Ps:这里是晨曦个人的理解,当然欢迎大家在评论区进行讨论,但是针对无法离散化的连续型数据大部分都是数据量比较小的,这种情况应该也不太建议进行模型的构建,因为不管什么算法,都需要充足的数据量作为前提
1. 首次揭秘!不做实验也能发10+SCI,CNS级别空间转录组套路全解析(附超详细代码!)
3. 太猛了!万字长文单细胞分析全流程讲解,看完就能发文章!建议收藏!(附代码)
4. 秀儿!10+生信分析最大的难点在这里!30多种方法怎么选?今天帮你解决!
5. 图好看易上手!没有比它更适合小白入手的单细胞分析了!老实讲,这操作很sao!
1. 宝儿,5min掌握一个单细胞数据库,今年国自然就靠它了!(附视频)
3. 想白嫖、想高大上、想有高大上的SCI?这个单细胞数据库,你肯定用得上!(配视频)
7. 大佬研发的单细胞数据库有多强? 别眼馋 CNS美图了!零基础的小白也能10分钟学会!
8. 纯生信发14分NC的单细胞测序文章,这个北大的发文套路,你可以试下!实在不行,拿来挖挖数据也行!
10. 生信数据挖掘新风口!这个单细胞免疫数据库帮你一网打尽了!SCI的发文源头!
- 本文固定链接: http://www.douyinyunying.cc/?id=25717
- 转载请注明: admin 于 抖音运营 发表
《本文》有 0 条评论